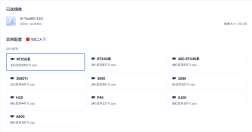
AI漫剧-主工作流
{
"name": "AI漫剧-主工作流",
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-32,
432
],
"id": "66cd9192-a02b-472d-8a4c-d5224e12dce5",
"name": "When clicking ‘Execute workflow’"
},
{
"parameters": {
"promptType": "define",
"text": "=你是一位经验丰富的影视制片人和资源管理专家,擅长分析剧本并识别制作所需的关键物料。现在你需要将可视化的影视文本进行场景分解,并识别出需要固定形象的物料。\n\n## 你的任务目标\n\n将可视化文本按\"场景+时间段\"的维度进行结构化分解,识别出需要跨章节保持视觉一致性的关键物料(主要角色、场景)。\n\n## 核心理解\n\n**为什么要识别物料?**\n- 识别出的角色、场景会生成固定的基础图片\n- 这些图片会在后续章节中复用,确保整部作品的**视觉一致性**\n- 非主要角色不需要固定形象,可以随场景动态生成\n\n**识别标准**:只识别需要跨章节保持一致性的关键物料。\n\n## 场景分解规则\n\n### 1. 场景划分标准\n按照\"**地点+时间段**\"的组合进行划分,只要满足以下任一条件就分为新场景:\n\n**地点变化**:\n- 地点有细微变化就分为新场景\n- 例如:\"山顶\"→\"山脚\"→\"山洞内部\" 是三个不同场景\n- 例如:\"客厅\"→\"卧室\"→\"厨房\" 是三个不同场景\n- 例如:\"街道\"→\"咖啡馆\"→\"办公室\" 是三个不同场景\n\n**时间段变化**:\n- 在同一地点,时间段变化也要分为新场景\n- 时间段只需标注大致时段:**白天/夜晚/傍晚/清晨/中午**等\n- 例如:\"山顶,清晨\"和\"山顶,傍晚\"是两个不同场景\n\n**原因**:即使是临时场景,后续拆分分镜时也可能有多个镜头。如果多个镜头中的场景图片不一致,会产生严重的违和感。因此**所有出现的场景都必须识别**。\n\n**重要**:相同场景+相同时间段的连续剧情应该合并为一个场景对象,不要因为story字段内容较长就拆分为多个场景对象。\n\n### 2. 场景命名规范\n- 格式:\\`地点,时间段\\`\n- 地点要具体明确,能让人清晰理解是什么地方\n- 时间段用通用词汇:白天/夜晚/傍晚/清晨/中午/深夜等\n- **同一大场景内的不同位置要分开**:例如\"水帘洞内部\"和\"水帘洞王座\"应视为同一场景,统一为\"水帘洞内部\"\n\n**场景粒度把握**:\n- ✅ 正确粒度:\"客厅\"、\"卧室\"、\"厨房\"(室内不同房间要分开)\n- ✅ 正确粒度:\"山顶\"、\"山脚\"、\"山腰\"(大范围地点的不同位置要分开)\n- ❌ 过细粒度:\"客厅沙发处\"、\"客厅电视前\"(同一房间的不同位置不要分开)\n- ❌ 过细粒度:\"水帘洞内部\"、\"水帘洞王座\"(同一洞穴的不同位置不要分开)\n\n**重要:场景合并原则**\n在相同时间段内,如果剧情在同一个大地点的不同小位置之间连续发生,应该合并为一个场景:\n- ✅ 正确:\"我家,中午\"(包含厨房→客厅→卧室的连续剧情)\n- ✅ 正确:\"公司,上午\"(包含大厅→走廊→办公室的连续剧情)\n- ❌ 错误:将\"厨房,中午\"、\"客厅,中午\"、\"卧室,中午\"拆分为三个场景(剧情连续,应合并)\n- ❌ 错误:将\"山脚,白天\"、\"山腰,白天\"、\"山顶,白天\"合并为一个场景(地点跨度大,应分开)\n\n**判断标准**:\n- 如果是室内场景,同一建筑物内的不同房间在连续剧情中应合并(如\"家\"、\"公司\"、\"酒店\")\n- 如果是室外场景,地点跨度较大时仍需分开(如\"山脚\"→\"山顶\")\n- 关键看剧情的连贯性和地点的归属性\n\n**示例**:\n- ✅ \"花果山山顶,白天\"\n- ✅ \"水帘洞内部,白天\"(不要再细分为\"水帘洞王座\")\n- ✅ \"张三的卧室,夜晚\"\n- ✅ \"咖啡馆,傍晚\"\n- ❌ \"第三天清晨的山顶\"(太具体)\n- ❌ \"山上\"(太模糊)\n- ❌ \"水帘洞王座\"(过细,应归入\"水帘洞内部\")\n\n## 物料识别规则\n\n### 1. 角色识别\n**只识别在当前章节实际出场的角色,若只是提到,缺没有出场,则不需要识别该角色**\n\n**识别标准**:\n- ✅ 有具体名字的角色(如\"孙悟空\"、\"张三\"、\"李小姐\")\n- ✅ 有特定称号的主要角色(如\"美猴王\"、\"老板\"、\"教授\")\n- ✅ 有特定称号的主要角色(如\"前台女孩\"、\"店员\"、\"路人甲\")\n- ✅ 第一人称叙述中的\"我\"(保持使用\"我\"作为角色名)\n- ❌ 群体角色(如\"众猴\"、\"路人\"、\"士兵们\")\n- ❌ 旁白/画外音(不算角色)\n\n**第一人称处理**:\n- 如果小说采用第一人称\"我\"叙述,直接使用\"我\"作为角色名\n- 不要试图推断或替换为其他名称\n- 在 \\`characters\\` 数组中,\"我\"和其他角色名并列即可\n\n**角色名称一致性原则**:\n- **同一角色的不同称呼必须统一为一个名称**\n- 选择该角色最常用、最正式的称呼作为统一名称\n- 例如:\"石猴\"在故事后期被称为\"美猴王\",应统一使用\"石猴\"或\"美猴王\"其中一个\n- 例如:\"张三\"如果也被称为\"张老板\"、\"张先生\",应统一使用\"张三\"\n\n**处理方式**:\n- 在 \\`characters\\` 数组中:只列出**在该场景中真正出场**的主要角色,同一角色只出现一次\n- 在 \\`story\\` 文本中:保留所有角色描述(包括\"众猴\"、\"路人\"等)\n- **只要角色在该场景中出现(哪怕是在场景末尾才出现、刚刚诞生、刚刚登场),都应该被识别**\n\n**重要说明**:\n- \\`characters\\` 数组表示的是**在该场景画面中实际出现的角色**\n- 如果某角色只是被提及、回忆或讨论,但没有实际出现在场景中,不应该列入 \\`characters\\`\n- 例如:芳姐在对话中提到\"那个医生\",但医生本人没有在场,不要把医生列入该场景的 \\`characters\\`\n\n### 2. 场景识别\n**所有出现的场景都要识别**,每个场景都需要生成固定的背景图片。\n**只识别实际出场的场景,若该场景只是提到,并没有实际出场,则不需要识别**\n\n- 无论场景是否会反复出现,都要识别\n- 包括临时出现的场景(如\"街角\"、\"走廊\")\n- 每个场景都会生成一张固定的背景图,供后续分镜使用\n\n## 输出数据结构\n\n输出一个JSON对象,包含一个 scenes 数组字段,每个元素代表一个场景:\n\n\\`\\`\\`json\n{\n \"scenes\": [\n {\n \"scene\": \"场景名称(地点,时间段)\",\n \"story\": \"该场景的完整剧情文本(从可视化文本中截取)\",\n \"characters\": [\"主要角色1\", \"主要角色2\"],\n }\n ]\n}\n\\`\\`\\`\n\n**字段说明**:\n- scenes:场景列表数组\n- scene:场景名称,格式为\"地点,时间段\"\n- story:该场景内的完整剧情文本,包括所有动作描述、对话、情绪描述、[内心独白:...] 标注等。直接从输入的可视化文本中截取对应场景的段落。\n- characters:该场景中出现的主要角色名称数组(只包含有名字的角色,不包括群体角色)\n\n## 注意事项\n\n1. **场景必须完整覆盖**:确保所有剧情都被分配到某个场景中,不能有遗漏\n2. **story字段保持原样**:直接从输入文本中截取,保留所有格式、标注(如[内心独白:...])\n3. **角色名称统一**:同一角色在不同场景中名称要保持一致\n4. **输出格式**:必须输出包含 scenes 数组的 JSON 对象\n\n---\n\n## 现在开始你的任务\n\n请将以下可视化文本进行场景分解并识别物料:\n{{ $json.story }}\n",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
672,
432
],
"id": "65f1f0a9-141b-411e-b295-ee1003c08ab7",
"name": "AI Agent1",
"retryOnFail": true
},
{
"parameters": {
"jsonSchemaExample": "[\n {\n \"scene\": \"\",\n \"story\": \"\",\n \"characters\": [\"张三\", \"李四\"]\n }\n]"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
848,
624
],
"id": "59057da6-03f0-46d6-8d02-50c58b1ff0af",
"name": "Structured Output Parser1"
},
{
"parameters": {
"jsCode": "const data = $input.first().json.output\n// 提取并去重\nconst scenes = [...new Set(data.map(item => item.scene))];\nconst characters = [...new Set(data.flatMap(item => item.characters))];\n\n// 输出结果\nconsole.log('场景列表:', scenes);\nconsole.log('角色列表:', characters);\n\n// 或者输出为对象格式\nconst result = {\n scenes,\n characters\n};\n\nreturn result"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
992,
432
],
"id": "e5658d7f-8155-4ba8-ae66-e6399beb45d2",
"name": "Code in JavaScript"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "f57616f3-8289-40e2-ab0e-1f80f9ea0f78",
"name": "scenes",
"value": "={{ $json.scenes }}",
"type": "array"
},
{
"id": "c2ee0540-634e-4922-bec8-ec62906a273d",
"name": "characters",
"value": "={{ $json.characters }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
1216,
432
],
"id": "2db12528-a177-45af-82f4-ccf3f13aec4b",
"name": "Edit Fields1"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
1504,
704
],
"id": "0697b128-3f38-47a3-aac2-460bfdd5f86b",
"name": "DeepSeek Chat Model2",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"jsonSchemaExample": "[\n {\n \"name\": \"角色名称(与输入的角色名称完全一致)\",\n \"prompt\": \"用于图片生成的中文prompt,Stable Diffusion格式,逗号分隔,必须包含'纯白背景'\",\n \"description\": \"角色的中文描述,自然语句,50-100字\",\n \"appearance\":\"\"\n }\n]"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
1664,
704
],
"id": "b3b0b9ea-bab1-403b-b07a-cc0142d3ac37",
"name": "Structured Output Parser2"
},
{
"parameters": {
"jsonSchemaExample": "[\n {\n \"name\": \"场景名称(与输入的场景名称完全一致)\",\n \"prompt\": \"用于图片生成的中文prompt,Stable Diffusion格式,逗号分隔\",\n \"description\": \"场景的中文描述,自然语句,50-100字\"\n }\n]"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
1664,
1120
],
"id": "e5f10e2f-9d21-411c-b889-5623034709d7",
"name": "Structured Output Parser3"
},
{
"parameters": {
"promptType": "define",
"text": "=你是一名资深的角色设计师和AI提示词描述师,擅长将文字描述转换为精准的角色形象提示词。现在你需要为小说中的角色生成用于AI图片生成的prompt。\n\n## 你的任务目标\n\n根据小说章节内容和角色名称列表,为每个角色生成详细的图片生成prompt(中文,Stable Diffusion格式)和角色描述。\n\n## 核心理解\n\n**角色图片的作用**:\n- 角色图片是固定的人物形象,会在后续的所有章节中复用\n- 必须确保**跨章节的视觉一致性**\n- 一个角色只有一个固定形象\n\n**角色形象的固定性**:\n- 外貌、发型、体型、服装、服饰必须固定\n- 这些要素共同构成角色的唯一形象\n- **不考虑**角色在不同场景下的服装变化\n- **不考虑**角色的表情、动作、姿态等可变要素\n\n**图片要求**:\n- **必须是白色背景**\n- 角色居中展示\n- 必须使用半身照\n\n## 角色prompt生成规则\n\n### 1. 提示词固定格式\n\n**标准结构(必须严格遵守)**:\n{artStyle},超细腻面部表情,性别,年龄,身高,脸型,发型,眼型,简化鼻子和嘴(线条嘴、线条鼻子),瞳色,眼神,身材,服装款式颜色(干净无污染、色块统一且无杂色的材质),纯白背景,半身照\n\n**具体描述顺序(必须按此顺序)**:\n1. 性别\n2. 年龄(具体数字,如\"23岁\")\n3. 身高(具体数字,如\"168cm\")\n4. 脸型(如\"鹅蛋脸\"、\"棱角分明脸型\")\n5. 发型(详细描述,如\"墨色高马尾\"、\"深紫色半束发\")\n6. 眼型(如\"杏眼\"、\"狭长凤眼\")\n7. 简化鼻子和嘴(固定用\"线条嘴、线条鼻子\")\n8. 瞳色(具体颜色,如\"青绿色瞳孔\"、\"暗紫色瞳孔\")\n9. 眼神(如\"眼神锐利\"、\"眼神阴鸷\")\n10. 身材(如\"身材E杯细腰\"、\"宽肩窄腰\")\n11. 服装款式颜色(详细描述,如\"月白色交领短衫+石青色束腰长裙\")\n12. 纯白背景(必须包含)\n13. 半身照\n\n### 2. 提示词要求\n\n- **只描写简单的物理状态**:只保留特征主体\n- **不描述光影**:光影已在艺术风格中统一定义\n- **不描述唇色**:统一使用简化的线条嘴\n- **色块统一**:避免杂色和复杂图案\n- **内容简洁明了**:严禁深入叙述\n- **全部为物理状态呈现**:无拟人化,无比喻等词语\n\n### 3. 必须包含的要素\n\n**外貌特征**(核心):\n- 面部特征:脸型、眼型、简化鼻嘴\n- 年龄和性别(具体数字)\n- 身高(具体数字)\n- 种族或特殊物种(人类、猴子、妖怪等)\n\n**体型特征**:\n- 身材描述(具体、简洁)\n- 体态(挺拔、佝偻等)\n\n**发型**:\n- 发型样式(详细)\n- 发色(具体颜色)\n\n**服装服饰**(重要):\n- **服装形制**(根据身份和职业确定)\n- **服装款式**(详细描述)\n- **服装颜色**(具体颜色名称)\n- **材质说明**(干净、色块统一)\n- **不包含鞋子**\n\n**眼神气质**:\n- 瞳色(具体颜色)\n- 眼神特点(一个形容词)\n\n### 4. 绝对禁止的内容\n\n❌ **绝对禁止**包含以下内容:\n- 具体的表情(微笑、愤怒、悲伤等)\n- 具体的动作(跑、跳、挥手等)\n- 具体的姿态(弯腰、抬手等)\n- 场景和背景元素(除了\"纯白背景\")\n- 道具和物品(除非是角色服装的固定组成部分)\n- 其他角色\n- 鞋子\n- 光影描述\n- 唇色描述\n\n## 输出数据结构\n\n输出一个包含 characters 数组的 JSON 对象:\n{\n \"characters\": [\n {\n \"name\": \"角色名称(与输入的角色名称完全一致)\",\n \"prompt\": \"用于图片生成的中文prompt,Stable Diffusion格式,逗号分隔,必须包含'纯白背景'\",\n \"description\": \"角色的中文描述,自然语句,50-100字\",\n \"appearance\": \"角色最精简的外在形象描述,10字左右\"\n }\n ]\n}\n\n## 注意事项\n\n1. **严格遵守角色名称**:输出的 name 字段必须与输入的角色名称完全一致\n2. **必须包含纯白背景**:prompt中必须明确指定\"纯白背景\"\n3. **不包含表情动作**:只描述固定的外貌、发型、体型、服装\n4. **服装必须固定**:为角色设计一套固定的服装\n5. **基于小说内容**:仔细阅读小说中该角色的描写\n6. **符合角色设定**:服装和形象要符合角色的身份、年龄、性格\n7. **保持风格一致性**:所有prompt的格式和结构必须统一\n8. **输出纯JSON对象**:必须输出包含 characters 数组的 JSON 对象\n9. **色彩管理**:确保不同角色有明显的视觉区分度\n10. **差异性**:每个人物的服装必须有较大的差异,如服装颜色、款式,每个人物都不能相同。\n\n---\n\n## 现在开始你的任务\n\n**输入数据**:\n\n角色列表:\n{{ $json.characters }}\n\n小说章节原文:\n{{ $('视频配置').item.json.story }}\n\n艺术风格:\n{{ $('视频配置').item.json.art_style }}\n\n---\n请为以上所有角色生成图片prompt和描述。",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
1520,
544
],
"id": "61f95025-22d1-4be0-a8fb-b26f846b5813",
"name": "人物",
"retryOnFail": true
},
{
"parameters": {
"promptType": "define",
"text": "=你是一位经验丰富的场景美术设计师和概念艺术家,擅长将文字描述转换为精准的图片生成提示词。现在你需要为小说中的场景生成用于AI图片生成的prompt。\n\n## 你的任务目标\n\n根据小说章节内容和场景名称列表,为每个场景生成详细的图片生成prompt(中文,Stable Diffusion格式)和场景描述。\n\n## 核心理解\n\n**场景图片的作用**:\n- 场景图片是固定的背景图,会在后续的多个分镜中复用\n- 必须确保视觉一致性,避免每次生成都不一样\n- 场景图片**不包含人物和道具**,只包含环境本身\n\n**场景命名格式**:\n- 格式为 `地点,时间段`\n- 例如:\"花果山山顶,白天\"、\"水帘洞内部,白天\"、\"卧室,夜晚\"\n\n## 场景prompt生成规则\n\n### 1. 艺术风格约束(必须遵守)\n\n- **所有场景prompt必须用以下艺术风格作为前缀,放在prompt的最开头:**\n{{ $('视频配置').item.json.art_style }}\n\n### 2. 场景空间推断原则(核心)\n\n**场景不是单一局部,而是故事发生的完整场所**。你必须根据以下维度进行推断:\n\n**空间推断维度**:\n1. **使用功能**:这个场景是用来做什么的?(居住、战斗、集会、办公等)\n2. **容积大小**:根据功能推断场景的范围和空间大小(小房间 vs 大厅 vs 广场)\n3. **空间高度**:根据功能和容积推断天花板/顶部高度(低矮 vs 挑高 vs 露天)\n4. **最大角色数量**:剧本中该场景曾经同时出现的最大角色数量,推断场景需要容纳的空间\n\n**空间关系描述(必须包含)**:\n- 场景的整体范围和边界\n- 场景内各元素的**位置关系**(前后、左右、中央、角落等)\n- 场景内各元素的**空间层次**(前景、中景、远景)\n- 建筑构件的**相互关系**(门窗位置、家具摆放、通道走向等)\n\n**建筑构件识别**:\n- 从剧本中提取明确指出的建筑构件(门、窗、桥、柱子、台阶等)\n- 根据场景功能推断必要的建筑构件(如卧室必有床,咖啡馆必有桌椅)\n\n### 3. prompt必须包含的要素\n\n**地点特征**(核心):\n- 场景的整体范围和空间大小(根据功能和角色数量推断)\n- 场景的空间高度(低矮、正常、挑高、露天等)\n- 场景的整体布局和空间结构\n- 场景的主要元素及其**位置关系**(建筑、地形、植被、装饰等)\n- 场景的材质和质感(石头、木头、金属等)\n\n**光照和时间段**(必须):\n- 根据场景名称中的时间段(白天/夜晚/傍晚/清晨等)描述光照条件\n- 例如:\"白天\" → \"明亮的阳光,柔和的光影\"\n- 例如:\"夜晚\" → \"月光,柔和的夜色,星光点点\"\n- 例如:\"傍晚\" → \"夕阳余晖,温暖的橙色光线\"\n\n**氛围和情绪**:\n- 从小说内容中提取该场景的整体氛围\n- 例如:宁静、神秘、宏伟、温馨、压抑等\n\n**视角和构图**:\n- 指定合适的视角(俯瞰、平视、仰视等)\n- 指定景深和构图方式\n\n### 4. prompt不能包含的内容\n\n❌ **绝对禁止**包含以下内容:\n- 人物(任何角色、人影、人物轮廓)\n- 道具(任何可移动的物品)\n- 动态元素(飞鸟、流水除外,作为场景装饰可以)\n- 具体的情节或动作\n\n### 5. prompt格式要求\n\n- **语言**:中文\n- **格式**:Stable Diffusion风格,使用逗号分隔关键词\n- **结构**:艺术风格,场景范围大小,空间高度,主体描述,元素位置关系,材质质感,光照条件,氛围情绪,视角构图,画质要求\n- **长度**:每个prompt控制在150-250字(因为需要详细描述空间关系)\n\n**标准模板**:\n\n[艺术风格],[场景范围和容积],[空间高度],[场景主体],[空间布局结构],[主要元素及位置关系],[建筑构件及相互关系],[材质质感],[光照条件],[氛围情绪],[视角构图],高质量,细节丰富,概念艺术\n\n\n### 6. 场景描述(description)要求\n\n- 用**自然的中文语句**描述场景\n- 说明场景的用途、特点、氛围、空间感\n- 长度控制在50-100字\n- 便于人类阅读理解\n\n## 场景空间推断方法\n\n在生成prompt之前,你必须先进行**空间推断分析**。以下是推断步骤:\n\n### 步骤1:分析场景功能\n- 这个场景的主要用途是什么?(居住、战斗、集会、办公、休闲等)\n- 功能决定了场景需要的基本空间大小\n\n### 步骤2:统计角色数量\n- 查看剧本中该场景同时出现的**最大角色数量**\n- 1-2人:小空间(10-50平米)\n- 3-5人:中小空间(50-100平米)\n- 6-10人:中型空间(100-200平米)\n- 10人以上:大型空间(200平米以上)\n\n### 步骤3:推断空间尺度\n- **容积大小**:根据功能和人数确定平面范围(平米数)\n- **空间高度**:\n - 小房间/密闭空间:2.5-3米\n - 普通室内:3-4米\n - 大厅/洞穴:5-10米\n - 宫殿/大型建筑:10米以上\n - 露天场景:无限高度\n\n### 步骤4:确定空间关系\n- **前景-中景-远景**:场景从近到远有哪些元素层次?\n- **左-中-右**:各元素分布在空间的哪个位置?\n- **建筑构件位置**:门窗在哪里?桥连接哪里?家具如何摆放?\n\n## 示例\n\n### 示例1:自然场景(露天大空间)\n\n**输入**:\n- 场景名称:\"花果山山顶,白天\"\n- 小说片段:\"那座山正当顶上,有一块仙石...四面更无树木遮阴,左右倒有芝兰相衬\"\n- 场景分析:露天自然场景,无建筑遮挡,空间开阔,主要用于展示仙石诞生,角色数量1-2人\n\n**输出**:\n{\n \"name\": \"花果山山顶,白天\",\n \"prompt\": \"{{ $('视频配置').item.json.art_style }},开阔的山顶平台约50平米范围,露天无遮挡,仙山之巅,巨大的圆形仙石矗立在山顶平台中央位置,高约3米,仙石周围四面空旷无树木,左侧和右侧各生长着仙草灵芝和兰花作为点缀,远处背景可见云海翻滚环绕山峰,蓝天白云,明亮的阳光从上方洒落照亮整个山顶,仙气在空中缭绕,宏伟壮丽的氛围,广角俯瞰视角能看到整个山顶平台和周围云海,景深效果,高质量,细节丰富,概念艺术\",\n \"description\": \"花果山的最高峰露天山顶平台,约50平米的开阔空间,中央矗立着巨大仙石,四周空旷,左右两侧点缀仙草灵芝,云海环绕,仙气飘渺,给人宏伟神秘的空间感。\"\n}\n\n\n### 示例2:室内场景(中型洞穴空间)\n\n**输入**:\n- 场景名称:\"水帘洞内部,白天\"\n- 小说片段:\"原来是座铁板桥...桥那边有一座天造地设的家当...石座石床,石盆石碗\"\n- 场景分析:洞穴居住空间,用于群居生活,曾出现众猴(10人以上),需要容纳多人活动和生活家具\n\n**输出**:\n{\n \"name\": \"水帘洞内部,白天\",\n \"prompt\": \"{{ $('视频配置').item.json.art_style }},宽敞的石洞大厅空间约200平米,洞顶高度约8-10米呈拱形,洞穴内部前景入口处有瀑布水帘遮挡形成朦胧光影,洞内中景位置有铁板桥横跨连接两侧地面,桥后方远景区域石制家具整齐摆放成生活区,包括石座石床石桌分布在洞穴两侧和后方,左右两侧天然石柱支撑洞顶,岩石质感粗糙自然带有湿润感,从瀑布透进的柔和日光照亮前景和中景,洞内光线昏暗但有光斑洒在石制家具上,神秘清幽的氛围,平视角度从入口看向洞穴深处,纵深构图展现空间层次,高质量,细节丰富,概念艺术\",\n \"description\": \"水帘洞的主洞厅,约200平米的宽敞洞穴空间,洞顶高约8-10米,入口瀑布水帘遮挡,中央铁板桥连接两侧,内部石制家具分布两侧和后方,光线从瀑布透入形成层次感,营造神秘清幽的居住氛围。\"\n}\n\n\n### 示例3:城市场景(小型室内空间)\n\n**输入**:\n- 场景名称:\"咖啡馆,傍晚\"\n- 小说片段:\"这是一家温馨的小咖啡馆,靠窗的位置摆放着几张木桌,墙上挂着暖色调的装饰画\"\n- 场景分析:小型商业空间,用于休闲会面,最多容纳2-3个角色对话,需要展示窗边座位和吧台区\n\n**输出**:\n{\n \"name\": \"咖啡馆,傍晚\",\n \"prompt\": \"{{ $('视频配置').item.json.art_style }},温馨的小咖啡馆室内空间约40平米,层高约3米,前景右侧靠窗位置摆放3-4张木质桌椅,左侧墙面挂着暖色装饰画,中景位置是吧台区域摆放咖啡机和杯具,吧台后方是操作区,室内左右两侧墙面和顶部暖黄色吊灯形成照明,大玻璃窗位于右侧墙面,复古温馨的装饰风格,傍晚时分夕阳余晖从右侧窗户透进洒在木桌和地面上,温暖的橙色光线与室内灯光交织,温馨舒适的氛围,平视角度从门口向内看整个空间布局,浅景深突出前景座位区,高质量,细节丰富,概念艺术\",\n \"description\": \"一家约40平米的小型咖啡馆室内空间,层高3米,右侧窗边摆放木质桌椅,左侧墙面装饰画,中央吧台区,傍晚夕阳从窗户透入,与室内暖黄灯光交织,营造温馨舒适的休闲氛围。\"\n}\n\n\n## 输出数据结构\n\n输出一个JSON数组,每个元素代表一个场景:\n[\n {\n \"name\": \"场景名称(与输入的场景名称完全一致)\",\n \"prompt\": \"用于图片生成的中文prompt,Stable Diffusion格式,逗号分隔\",\n \"description\": \"场景的中文描述,自然语句,包含空间信息,50-100字\"\n }\n]\n\n\n## 注意事项\n\n1. **必须包含艺术风格**:所有prompt必须以我指定的艺术风格开头,这是强制要求\n2. **必须进行空间推断**:根据场景功能、角色数量推断空间大小、高度、容积\n3. **必须描述空间关系**:详细说明各元素的位置关系(前景、中景、远景,左侧、右侧、中央等)\n4. **严格遵守场景名称**:输出的 `name` 字段必须与输入的场景名称完全一致\n5. **绝对不能包含人物**:prompt中不能出现任何人物相关描述\n6. **绝对不能包含道具**:prompt中不能出现可移动的道具物品\n7. **时间段必须体现**:根据场景名称中的时间段(白天/夜晚等)准确描述光照\n8. **基于小说内容**:仔细阅读小说中该场景的描写,提取关键的场景元素\n9. **提取建筑构件**:从剧本中明确提到的建筑构件必须包含(门、窗、桥等)\n10. **保持风格一致性**:所有prompt的格式和结构应该统一\n11. **输出纯JSON**:不要添加任何解释性文字,只输出JSON数组\n\n---\n\n## 现在开始你的任务\n\n**输入数据**:\n\n场景列表:\n{{ $('Edit Fields1').item.json.scenes }}\n\n\n小说章节原文:\n{{ $('视频配置').item.json.example_text }}\n\n\n请为以上所有场景生成图片prompt和描述。\n",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
1504,
912
],
"id": "5425a48a-2013-4517-81e5-a898559228eb",
"name": "场景",
"retryOnFail": true
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "385dbf4c-8b7a-4b45-b95b-8b5a9c77ff21",
"name": "output_folder_path",
"value": "=/data/",
"type": "string"
},
{
"id": "e4dde0ac-2108-4a9b-90c9-0d40a8898d49",
"name": "文生图工作流id",
"value": "",
"type": "string"
},
{
"id": "ebcc4f6d-c941-44ad-ae53-e095e0c3b39e",
"name": "生成分镜图片-批量-工作流id",
"value": "",
"type": "string"
},
{
"id": "96e584a7-eede-4225-bd08-f005eae5f539",
"name": "生成视频片段-批量-工作流id",
"value": "",
"type": "string"
},
{
"id": "d4d8af67-8976-4f08-b88f-344215dd7da0",
"name": "生成分镜图片-工作流id",
"value": "",
"type": "string"
},
{
"id": "baeb3bd0-7a14-4121-b621-dd73af76f26b",
"name": "生成视频片段-工作流id",
"value": "",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
176,
432
],
"id": "2213b3fc-a072-4d8c-b954-2de6d9807824",
"name": "基础字段"
},
{
"parameters": {
"fieldToSplitOut": "output",
"options": {}
},
"type": "n8n-nodes-base.splitOut",
"typeVersion": 1,
"position": [
1872,
544
],
"id": "f48dea5c-79b5-40aa-a2d1-e9ab5882fc24",
"name": "Split Out"
},
{
"parameters": {
"options": {}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
2080,
544
],
"id": "35f926dc-53f5-4120-baa1-770d208f6c3d",
"name": "Loop Over Items"
},
{
"parameters": {
"fieldToSplitOut": "output",
"options": {}
},
"type": "n8n-nodes-base.splitOut",
"typeVersion": 1,
"position": [
1856,
912
],
"id": "82326033-b095-4d16-b933-90a545c40f51",
"name": "Split Out1"
},
{
"parameters": {
"options": {}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
2064,
912
],
"id": "ce413a43-3086-43e8-96bf-fe95176f31ff",
"name": "Loop Over Items1"
},
{
"parameters": {
"workflowId": {
"__rl": true,
"value": "={{ $('基础字段').first().json['文生图工作流id'] }}",
"mode": "id",
"cachedResultUrl": "/workflow/=%7B%7B%20$('%E5%9F%BA%E7%A1%80%E5%AD%97%E6%AE%B5').first().json['%E6%96%87%E7%94%9F%E5%9B%BE%E5%B7%A5%E4%BD%9C%E6%B5%81id']%20%7D%7D"
},
"workflowInputs": {
"mappingMode": "defineBelow",
"value": {
"height": 810,
"prompt": "={{ $json.prompt }}",
"width": 1440
},
"matchingColumns": [],
"schema": [
{
"id": "prompt",
"displayName": "prompt",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "string",
"removed": false
},
{
"id": "width",
"displayName": "width",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "number",
"removed": false
},
{
"id": "height",
"displayName": "height",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "number",
"removed": false
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": true
},
"options": {}
},
"type": "n8n-nodes-base.executeWorkflow",
"typeVersion": 1.3,
"position": [
2336,
928
],
"id": "e49cd6b8-d632-44e1-8689-25c968c419a3",
"name": "Call 'AI漫剧-文生图'1"
},
{
"parameters": {
"aggregate": "aggregateAllItemData",
"options": {}
},
"type": "n8n-nodes-base.aggregate",
"typeVersion": 1,
"position": [
2784,
528
],
"id": "27a39c26-89c5-4500-9976-98bcf6944f55",
"name": "Aggregate"
},
{
"parameters": {
"aggregate": "aggregateAllItemData",
"options": {}
},
"type": "n8n-nodes-base.aggregate",
"typeVersion": 1,
"position": [
2752,
896
],
"id": "1f38691f-8a4f-47b5-be52-aec6eb0fc682",
"name": "Aggregate1"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "a56e6987-3fd4-42c4-88c8-2fba1ea2d769",
"name": "image_filepath",
"value": "={{ $json.image_filepath }}",
"type": "string"
},
{
"id": "08d57348-7165-4185-8393-9e97250e3de5",
"name": "name",
"value": "={{ $('Loop Over Items1').item.json.name }}",
"type": "string"
},
{
"id": "8e2905cf-694a-4629-a1ff-9d69cc398d90",
"name": "prompt",
"value": "={{ $('Loop Over Items1').item.json.prompt }}",
"type": "string"
},
{
"id": "e1a75fc1-c030-4122-a240-d8e75e448f97",
"name": "description",
"value": "={{ $('Loop Over Items1').item.json.description }}",
"type": "string"
},
{
"id": "84a40618-4511-4491-95a5-0b769dafb107",
"name": "image_url",
"value": "={{ $json.image_url }}",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
2544,
928
],
"id": "8617125c-324e-44ca-88cc-8a87051686e8",
"name": "Edit Fields7"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "a56e6987-3fd4-42c4-88c8-2fba1ea2d769",
"name": "image_filepath",
"value": "={{ $json.image_filepath }}",
"type": "string"
},
{
"id": "08d57348-7165-4185-8393-9e97250e3de5",
"name": "name",
"value": "={{ $('Loop Over Items').item.json.name }}",
"type": "string"
},
{
"id": "8e2905cf-694a-4629-a1ff-9d69cc398d90",
"name": "prompt",
"value": "={{ $('Loop Over Items').item.json.prompt }}",
"type": "string"
},
{
"id": "e1a75fc1-c030-4122-a240-d8e75e448f97",
"name": "description",
"value": "={{ $('Loop Over Items').item.json.description }}",
"type": "string"
},
{
"id": "ce494404-fcff-4799-8eda-2b3d59d8a686",
"name": "image_url",
"value": "={{ $json.image_url }}",
"type": "string"
},
{
"id": "38a820f7-954c-435a-9384-5213216d7169",
"name": "appearance",
"value": "={{ $('Loop Over Items').item.json.appearance }}",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
2592,
560
],
"id": "b7f5d27c-32de-4f73-ab3f-ff7d782631e2",
"name": "Edit Fields8"
},
{
"parameters": {
"numberInputs": 3
},
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2,
"position": [
640,
1424
],
"id": "a17e37d2-a4fa-4aa8-9181-e746b5179356",
"name": "Merge"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
1040,
2176
],
"id": "ce2cb439-d79e-4d1e-a7e6-e04bcceef93a",
"name": "DeepSeek Chat Model5",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"aggregate": "aggregateAllItemData",
"options": {}
},
"type": "n8n-nodes-base.aggregate",
"typeVersion": 1,
"position": [
800,
1440
],
"id": "069fbe5c-2fe2-406f-99e0-687c61d1a0d7",
"name": "Aggregate3"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "284691a8-9f71-4999-bfea-674dd701da97",
"name": "character_list",
"value": "={{ $json.data }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
3264,
528
],
"id": "e51066a6-1c5d-478e-a5d9-1eb8e75b32ba",
"name": "角色-整理"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "a6a1c5f7-9ce7-42c5-9a89-35005903617d",
"name": "scene_list",
"value": "={{ $json.data }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
3264,
896
],
"id": "da77bb67-423f-4b4e-ac66-e8e038a7b66a",
"name": "场景-整理"
},
{
"parameters": {
"jsCode": "return {\n data: $input.first().json.data.map(item => {\n const id = Date.now().toString(36) + Math.random().toString(36).substring(2);\n return {\n ...item,\n id\n }\n })\n}"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
2992,
528
],
"id": "8a667a54-7db5-4d2d-a42d-e3085719758a",
"name": "Code in JavaScript1"
},
{
"parameters": {
"jsCode": "return {\n data: $input.first().json.data.map(item => {\n const id = Date.now().toString(36) + Math.random().toString(36).substring(2);\n return {\n ...item,\n id\n }\n })\n}"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
2992,
896
],
"id": "70276906-fe12-467a-934c-e613f0e258af",
"name": "Code in JavaScript2"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
1680,
2176
],
"id": "1135453a-9551-4dbf-9fca-f62cc7324d2a",
"name": "DeepSeek Chat Model6",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
1440,
1120
],
"id": "97628d11-baaf-4eaf-b7b0-49afefa4ac7e",
"name": "DeepSeek Chat Model3",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"jsonSchemaExample": "[\n {\n \"duration\": \"\",\n \"text_covered\": \"\",\n \"visual_summary\": \"\",\n \"shots\": []\n }\n]"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
1232,
2176
],
"id": "74ed3419-99eb-4bc1-a4ae-3df9b70ace7e",
"name": "Structured Output Parser7"
},
{
"parameters": {
"jsonSchemaExample": "[{\n \"scene\": \"\",\n \"style\": \"\",\n \"mood\": \"\",\n \"sfx\": \"\",\n \"cinematography\": \"\"\n}]"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
1872,
2176
],
"id": "af9b7673-6ed4-45c3-a606-46e158893d77",
"name": "Structured Output Parser8"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
2336,
2176
],
"id": "df07390b-09fe-47fa-9e12-f3b23d67f912",
"name": "DeepSeek Chat Model9",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"jsonSchemaExample": "[\n {\n \"scene_index\": 1,\n \"character_ids\": [\"对应字典中的ID\"],\n \"panels\": [\n {\n \"panel_id\": 1,\n \"image_prompt\": \"场景是温馨的现代卧室,清晨阳光透过薄窗帘缝隙洒入,形成明显的丁达尔效应光柱。画面采用24mm广角的全景构图。光影呈现全局暖金色调,高调照明营造出清晨的氛围。画面定格在李明躺在床上的瞬间,被子盖到胸口,他正处于平静的睡眠呼吸状态。这是一个无对白的纯画面分镜,画面中没有气泡和文字。\"\n },\n {\n \"panel_id\": 2,\n \"image_prompt\": \"...\"\n }\n ]\n }\n]"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
2480,
2176
],
"id": "c7df0582-4f46-4795-b6d7-446b7ca7dac2",
"name": "Structured Output Parser9"
},
{
"parameters": {
"promptType": "define",
"text": "=# Role\n你是一位世界顶级的**漫画/分镜原画师**。你的任务是将一段\"动态的视频拍摄脚本\"转化为一组**\"静态的漫画分镜绘画提示词(Prompts)\"**。\n\n# Input Data\n1. **分镜描述数据:** {{ $json.data }}\n2. **角色名称字典:** {{ JSON.stringify($json.scene_character_list) }}\n\n# Task Logic (核心处理逻辑)\n你需要遍历每个场景,解析其中的 '分镜' 文本,为每个子分镜生成一段**流畅、自然的描述性提示词**,数量必须一致。\n\n### 关键转化规则 (必须严格遵守)\n\n**1. 降维:从\"时间流\"到\"关键帧\" (反鬼影机制)**\n视频脚本包含连续动作(时间流),而绘画只能表现瞬间(空间)。\n* **强制切片:** 你必须将连续动作切断,只选择**单一瞬间**进行描绘(如动作的起始帧 OR 结束帧)。\n* **禁用词汇:** 在生成的 Prompt 中,**严禁出现**表示时间流逝的连接词,如:“然后(then)”、“接着(after)”、“开始(starts to)”、“过程中(process of)”。\n* *Bad:* 李明从床上坐起,然后走向门口。(导致画面重影)\n* *Good:* 李明正坐在床边,身体微微前倾,呈现出准备站起的姿态。\n* *Good:* 李明走向门口的背影,手正伸向门把手。\n\n**2. 运镜转构图 (Motion to Composition)**\n视频运镜指令在绘图时无效,必须转换为静态构图描述:\n* **摇摄 (Pan):** 转化为 **\"Wide angle shot\" (广角)** 或 **\"Panorama\" (全景)**,强调场景的左右延伸感。\n* **推镜头 (Zoom In):** 转化为 **\"Close-up\" (特写)**,强调主体细节,背景虚化。\n* **跟拍 (Tracking):** 转化为 **\"Dynamic angle\" (动态视角)** 或 **\"Side view\" (侧视图)**,强调运动感。\n\n**3. 零气泡策略 (Textless Strategy)**\n* 如果原描述中 '[台词]' 为空或无:**严禁**在描述中提及\"对话\"、\"气泡\"或\"说话\"等词。并请在描述的末尾显式添加一句:\"这是一个无对白的纯画面分镜,画面中没有气泡和文字。\"\n* 只有当原描述明确有台词时,才允许描述:\"角色的台词以气泡形式展示,内容为:...\"。\n\n**4. 视觉一致性 (Visual Consistency)**\n* 必须保留原描述中的**光影设定**(如\"暖金色调\"、\"轮廓光\")和**环境细节**,将其自然地融入到画面描述中。\n\n# Output Format\n请输出一个 JSON 数组,结构如下:\n\n\\`\\`\\`json\n[\n {\n \"scene_index\": 1,\n \"character_ids\": [\"对应字典中的ID\"],\n \"panels\": [\n {\n \"panel_id\": 1,\n \"image_prompt\": \"场景是温馨的现代卧室,清晨阳光透过薄窗帘缝隙洒入,形成明显的丁达尔效应光柱。画面采用24mm广角的全景构图。光影呈现全局暖金色调,高调照明营造出清晨的氛围。画面定格在李明躺在床上的瞬间,被子盖到胸口,他正处于平静的睡眠呼吸状态。这是一个无对白的纯画面分镜,画面中没有气泡和文字。\"\n },\n {\n \"panel_id\": 2,\n \"image_prompt\": \"...\"\n }\n ]\n }\n]\n\\`\\`\\`\n\n请开始执行",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 3,
"position": [
2352,
1968
],
"id": "577af72d-76cd-42cf-9607-a234f3ec2049",
"name": "生成图片分镜",
"retryOnFail": true
},
{
"parameters": {
"jsCode": "const outputs = $input.first().json.output\n\nconst data = []\n\nfor (let index = 0; index < outputs.length; index++) {\n const output = outputs[index];\n const character = $input.first().json.output[index].character_ids.map(c => {\n \n const character_temp = $('角色-场景整理').first().json.character_list.find(c1 => c1.id === c)\n \n return {\n \"id\": character_temp.id,\n \"name\": character_temp.name,\n \"image_url\": character_temp.image_url,\n \"image_filepath\": character_temp.image_filepath\n }\n })\n \n const sence = output.panels.map(p => p.image_prompt);\n const p1 = sence.map((s,index) => `分镜${index + 1}:${s}`).join('\\n')\n const p2 = character.map((c, index) => `图${index + 1}的角色形象是'${c.name}'`)\n const p3 = index === 0 ? `图${character.length + 1}是场景参考图,仅作为艺术参考,不需要完全遵循构图` : `图${character.length + 1}是上个场景的参考图,你在生成新图时要参考图${character.length + 1},保持风格和上下文一致性。`\n const prompt = `**[构图强制指令]**\n 生成一张纵向排列的${sence.length}格长条漫画。采用**满版设计(Full Bleed)**,图像内容必须**填满画布的四个边缘**,**边缘处绝对禁止任何留白或画框**。仅在${sence.length}个分镜的上下连接处保留极细的白色分隔线。要求风格一致,角色台词使用气泡的形式展示。\\n风格为:${$('视频配置').first().json.art_style}。\\n${p1}\\n参考${p2}。要求保持人物形象细节不变。${p3}`\n data.push({\n index,\n prompt,\n character_image_url: character.map(c => c.image_url),\n scene_image_url: $('角色-场景整理').first().json.scene_list.find(s => s.id === $('分镜数据整理').first().json.scene.id).image_url,\n count: sence.length\n })\n}\n\nreturn {\n \"data\": data\n};"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
640,
2464
],
"id": "a0d2137e-f8ec-4414-a040-d155ef202314",
"name": "Code in JavaScript7"
},
{
"parameters": {
"jsCode": "const data = $input.first().json.output.map((item, index) => `场景${index+1}: ${item.scene}\\n${item.cinematography}\\n`).join('\\n')\n\nconst scene_character_list = $('分镜数据整理').first().json.characters.map(item => {\n return {\n name: item.name,\n id: item.id\n }\n})\n\nreturn {\n \"data\": data,\n \"scene_character_list\": scene_character_list\n}"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
2128,
1968
],
"id": "fd5bb3eb-d6bf-4358-a894-5db7ded21c86",
"name": "Code in JavaScript8"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "52bdf679-eed4-424b-8107-3390d5c3230c",
"name": "image_storyboards",
"value": "={{ $json.data }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
832,
2464
],
"id": "6e2a39ad-b25e-4178-9329-3d62b5407ae7",
"name": "最终图片分镜脚本整理"
},
{
"parameters": {
"model": "deepseek-reasoner",
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
624,
624
],
"id": "078cae65-e299-42bd-b222-d7317eb2d0a9",
"name": "DeepSeek Chat Model1",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"jsCode": "const characters_des = $('分镜数据整理').first().json.characters.map(item => `${item.appearance}形象的是${item.name}`).join('\\n')\n\nconst video_storyboards = $('sora2格式的视频分镜脚本').first().json.output.map((item, index) => {\n \n return {\n index,\n video_prompt: `${characters_des}\\n场景描述(scene):${item.scene}\\n风格(style):${$('视频配置').first().json.art_style}\\n氛围(mood):${item.mood}\\n背景音效(sfx):${item.sfx}\\n摄影(cinematography):${item.cinematography}\\n\\n生成的视频绝对禁止出现对话气泡`,\n image_url: $input.first().json.data[index].image_url\n }\n})\n\nreturn {\n \"video_storyboards\": video_storyboards\n}"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
1232,
2464
],
"id": "141b08d5-c2d4-4a8c-8c8b-ddbe4ae2b9f1",
"name": "数据整理"
},
{
"parameters": {
"workflowId": {
"__rl": true,
"value": "={{ $('基础字段').first().json['文生图工作流id'] }}",
"mode": "id",
"cachedResultUrl": "/workflow/=%7B%7B%20$('%E5%9F%BA%E7%A1%80%E5%AD%97%E6%AE%B5').first().json['%E6%96%87%E7%94%9F%E5%9B%BE%E5%B7%A5%E4%BD%9C%E6%B5%81id']%20%7D%7D"
},
"workflowInputs": {
"mappingMode": "defineBelow",
"value": {
"width": 810,
"prompt": "={{ $json.prompt }}",
"height": 1440
},
"matchingColumns": [],
"schema": [
{
"id": "prompt",
"displayName": "prompt",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "string",
"removed": false
},
{
"id": "width",
"displayName": "width",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "number",
"removed": false
},
{
"id": "height",
"displayName": "height",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "number",
"removed": false
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": true
},
"options": {}
},
"type": "n8n-nodes-base.executeWorkflow",
"typeVersion": 1.3,
"position": [
2384,
560
],
"id": "deb3ff2a-c6eb-40bb-8aae-2ab3c91db600",
"name": "Call 'AI漫剧-文生图'"
},
{
"parameters": {
"fieldToSplitOut": "scene_list",
"options": {}
},
"type": "n8n-nodes-base.splitOut",
"typeVersion": 1,
"position": [
1152,
1440
],
"id": "0c37a98a-4a27-46c0-936a-240dbabb28e8",
"name": "Split Out2"
},
{
"parameters": {
"options": {}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
1312,
1440
],
"id": "f7b2cc64-df98-4aa5-8724-f7d1901d0e51",
"name": "Loop Over Items2"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "7d84d47a-2f6e-487f-a9a4-fe30cecc4436",
"name": "character_list",
"value": "={{ $json.data[0].character_list }}",
"type": "array"
},
{
"id": "8e012737-a638-4d1f-8618-2fc920853583",
"name": "scene_list",
"value": "={{ $json.data[1].scene_list }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
992,
1440
],
"id": "ef9e3ba4-588c-415f-8d10-6c9f85f0e545",
"name": "角色-场景整理"
},
{
"parameters": {
"jsCode": "const index = $('角色-场景整理').first().json.scene_list.map(i => i.id).indexOf($input.first().json.id)\n\nconst story = $('AI Agent1').first().json.output[index].story\n\nreturn {\n \"index\": index,\n \"story\": story\n}\n"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
1552,
1440
],
"id": "e2382666-732e-47c5-a1a8-ca1440b4759f",
"name": "获取场景序号和场景对应故事"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
1712,
1680
],
"id": "93d72e2b-3342-496e-befc-37970a96b6a3",
"name": "DeepSeek Chat Model",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"jsonSchemaExample": "{\n\t\"summary\": \"\"\n}"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
1920,
1664
],
"id": "79605b03-db27-45f3-89b8-61bc8b9edfe6",
"name": "Structured Output Parser"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "79c7a9ab-7389-47d0-be99-5f27418c3bee",
"name": "summary",
"value": "={{ $json.output.summary }}",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
2064,
1440
],
"id": "53d10edc-cbe0-433e-ab14-4ce7c4ec8f9b",
"name": "Edit Fields2"
},
{
"parameters": {
"fieldsToAggregate": {
"fieldToAggregate": [
{
"fieldToAggregate": "summary"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.aggregate",
"typeVersion": 1,
"position": [
2288,
1440
],
"id": "a61490a1-e094-42c4-a365-77dfb74d3b64",
"name": "Aggregate2"
},
{
"parameters": {
"promptType": "define",
"text": "=你是一位专业的文本摘要专家。请为以下场景内容生成一个简洁的摘要,要求:\n1. 字数控制在100字以内\n2. 准确概括该场景的核心内容\n3. 包含关键动作和对话要点\n\n场景内容:\n{{ $json.story }}\n",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 3,
"position": [
1744,
1440
],
"id": "bc41fe91-235e-46e5-80dc-a480acd3f8e8",
"name": "生成场景故事摘要",
"retryOnFail": true
},
{
"parameters": {
"promptType": "define",
"text": "=你是一位专业的文本摘要专家。请为以下章节内容生成一个简洁的摘要,要求:\n1. 字数控制在100字以内\n2. 准确概括故事的核心发展\n3. 包含关键事件和转折点\n\n章节内容:\n {{ $('视频配置').first().json.story }}",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 3,
"position": [
2528,
1440
],
"id": "28730eb1-2434-419e-945d-11b35973739d",
"name": "生成整段故事摘要",
"retryOnFail": true
},
{
"parameters": {
"jsonSchemaExample": "{\n\t\"summary\": \"\"\n}"
},
"type": "@n8n/n8n-nodes-langchain.outputParserStructured",
"typeVersion": 1.3,
"position": [
2688,
1648
],
"id": "83dc0a48-3bbf-4f63-b0a4-a745f3eaefcd",
"name": "Structured Output Parser4"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
2512,
1648
],
"id": "e8da04b4-4fec-4c52-9d05-10b4d9fe9b40",
"name": "DeepSeek Chat Model4",
"credentials": {
"deepSeekApi": {
"id": "elAF6rwUnVPWlx9n",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "a2b0290c-742c-4ec2-8437-30ccca5aa6cb",
"name": "chapter_summary",
"value": "={{ $json.output.summary }}",
"type": "string"
},
{
"id": "2d98941e-8170-460a-bd85-aa4a7a62f6c3",
"name": "scene_summary",
"value": "={{ $('Aggregate2').item.json.summary }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
2832,
1440
],
"id": "37e2be87-e515-464f-82f3-d5a1aed4802b",
"name": "故事摘要整理"
},
{
"parameters": {
"jsCode": "const index = $('角色-场景整理').first().json.scene_list.map(i => i.id).indexOf($input.first().json.scene_list.id)\n\nconst scene_id = $input.first().json.scene_list.id\n \nconst story = $('AI Agent1').first().json.output[index]\n\nconst character_list = $('角色-整理').first().json.character_list\n\nconst characters = story.characters.map(item => {\n const character = character_list.find((c => c.name === item))\n return {\n name: item,\n \"description\": character.description,\n \"id\": character.id,\n \"appearance\": character.appearance\n }\n})\n\nreturn {\n \"scene\": {\n \"id\": scene_id,\n \"name\": story.scene\n },\n \"story\": story.story,\n \"characters\": characters,\n \"globalSummary\": $('故事摘要整理').first().json.chapter_summary,\n \"previousSummary\": index === 0 ? \"当前是第一个场景,无前情提要\" : $('故事摘要整理').first().json.scene_summary[index - 1],\n \"nextSummary\": index === $('角色-场景整理').first().json.scene_list.length - 1 ? '(暂无后续情节预告)' : $('故事摘要整理').first().json.scene_summary[index + 1]\n}\n"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
880,
1968
],
"id": "4911e49f-e59e-44d6-ac69-6a41cf55f293",
"name": "分镜数据整理"
},
{
"parameters": {
"fieldToSplitOut": "scene_list",
"include": "allOtherFields",
"options": {}
},
"type": "n8n-nodes-base.splitOut",
"typeVersion": 1,
"position": [
3232,
1440
],
"id": "9471cacb-50a3-4737-8433-878a8c099499",
"name": "Split Out3"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "e35fc0f9-5789-4b01-a02f-358a76f108aa",
"name": "scene_list",
"value": "={{ $('角色-场景整理').first().json.scene_list.map((item, index) => {\n return {\n ...item,\n index\n }\n}) }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
3040,
1440
],
"id": "f85a61ea-47e5-4dd3-9612-e750c13418af",
"name": "Edit Fields3"
},
{
"parameters": {
"promptType": "define",
"text": "=# Role\n你是一位精通Sora 2视频生成的动画分镜导演。你的任务是将一段小说文本转化为一系列**10秒的标准视频生成单元**。\n\n# Context Inputs (关键上下文)\n1. **全局故事摘要 (Global Context):**\n {{ $json.globalSummary }}\n\n2. **前情提要 (Previous Context - 摘要):**\n {{ $json.previousSummary }}\n\n3. **当前处理文本 (Current Text):**\n {{ $json.story }}\n\n4. **后续情节预告 (Next Context - 简述):**\n {{ $json.nextSummary }}\n\n5. **当前在场角色 (Active Characters):**\n {{ JSON.stringify($json.characters) }}\n\n# Task & Logic\n根据【当前处理文本】,设计**一个或多个**10秒的视频片段。\n* **如果文本很短**(如仅一个动作):扩展细节,生成 1 个 10秒片段。\n* **如果文本很长**(如长对话):按时间线拆分,生成 N 个 10秒片段(id: 1, id: 2...),确保覆盖所有剧情。\n\n# Constraints (Sora 2 专用)\n1. **时间容器:** 每个输出对象必须对应一段 **10秒** 的视频。\n2. **子镜头结构 (Sub-shots):** 在这10秒内,必须包含 **2-3个连续的子镜头**。利用景别变化(特写/全景)来丰富视觉,避免单调。注意!所有景别只能使用特写、半身近景或者中景,尽量只使用特写和半身近景,禁止使用全局或跟随镜头等!\n3. **子镜头原则** 如果剧情中存在多个角色,*尽量*不要让多个角色出现在同一个子镜头中!每个子镜头中尽量最多只能出现一个角色!\n4. **边界控制:** 严禁生成【后续情节预告】中的内容。\n5. **无旁白:** 将心理活动转化为微表情、肢体动作。\n\n# Output Format (JSON Array)\n输出一个JSON数组。如果当前文本需要生成30秒的视频才能讲完,数组里就应该有3个元素。\n\n示例格式:\n[\n {\n \"duration\": \"10s\",\n \"text_covered\": \"对应的原文片段(方便我核对)\",\n \"visual_summary\": \"李明在洗手间洗脸并注视镜子\",\n \"shots\": [\n \"镜头1 (3s): [特写] 水龙头打开,清澈的冷水哗啦流出,李明双手接水。\",\n \"镜头2 (4s): [近景] 李明把冷水泼在脸上,水珠飞溅,随后他抬起头看着镜子,神情逐渐聚焦。\",\n \"镜头3 (3s): [眼部特写] 镜子中李明的眼神,从原本的游移不定变得锐利,瞳孔中倒映着洗手间的灯光。\"\n ]\n }\n]",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
1088,
1968
],
"id": "a5f07733-aa03-4d62-bce7-01641a404e98",
"name": "生成剧本分镜描述的提示词",
"retryOnFail": true
},
{
"parameters": {
"promptType": "define",
"text": "=# Role\n你是一位精通Sora 2架构的**虚拟摄影指导(DP)**与**提示词工程师**。\n你的核心任务是:将接收到的【结构化分镜脚本】(Step 1 Output),翻译成**高精度、技术化**的Sora 2生成参数。\n\n# Input Data\n1. **分镜脚本数据 (Script Data):** \n{{ $json.scriptScenesText }}\n *(含场景及子镜头描述)*\n\n2. **角色引用表 (Reference):** {{ $json.characters }}\n *(确保角色名称准确)*\n\n3. **艺术风格 (Art Style):** {{ $('视频配置').first().json.art_style }}\n\n# Transformation Logic (处理逻辑)\n遍历输入数组的每个场景,转化为Sora 2标准JSON结构。\n\n1. **镜头映射 (Shot Mapping):**\n 严格映射 Step 1 的 'shots' 到输出的 '分镜N'。\n * Input Shot 1 -> Output 分镜1\n * Input Shot 2 -> Output 分镜2\n * **严禁**合并、拆分镜头或修改 'duration'。\n\n2. **技术参数化注入 (Technical Injection):**\n 使用专业术语增强质感。\n * **运镜术语:** 摇摄(Pan)、倾斜(Tilt)、推拉(Dolly In/Out)、跟拍(Tracking)、手持运镜(Handheld)。\n * **光影术语:** 体积光(Volumetric lighting)、轮廓光(Rim light)、伦勃朗光(Rembrandt lighting)、丁达尔效应(Tyndall effect)。\n * **镜头术语:** 广角(14mm-24mm)、标准(35mm-50mm)、特写(85mm-100mm)、浅景深(Shallow depth of field)。\n\n3. **动作细化 (Action Refinement):**\n 将简略动作转化为物理细节描述。\n * **关键约束:** 绝对**不要**描述角色的外貌(发型、衣着等)。只描述动作、表情和光影交互。\n\n# Critical Constraints (关键约束)\n1. **色调绝对一致性 (Strict Color Consistency):**\n 在一个场景(Scene)内部,所有分镜(分镜1、分镜2...)必须共享同一套**主色调与光影逻辑**。\n * *Bad:* 分镜1是暖黄晨光,分镜2变成了冷蓝荧光。\n * *Good:* 分镜1是暖黄晨光,分镜2依然是暖调,仅因角度变化产生阴影差异。\n2. **零外貌描述:** 严禁出现关于角色衣服、发型、身高的描述。\n3. **台词严格匹配:** 逐字保留原台词,不得修改。\n4. **时长守恒:** 确保 'cinematography' 中所有分镜的持续时间相加严格等于 10。\n\n# Output Format (Sora 2 Standard)\n请输出一个标准 JSON 数组,必须严格符合以下结构:\n\n\\`\\`\\`json\n[{\n \"scene\": \"场景环境描述(仅环境与天气,不含人)。例如:温馨的现代卧室,清晨阳光透过薄窗帘洒入,空气中漂浮着尘埃微粒。\",\n \"style\": \"{{ $('视频配置').first().json.art_style }}\",\n \"mood\": \"情绪基调。例如:紧张但充满希望\",\n \"sfx\": \"环境音效。例如:清脆的鸟叫声、闹钟的滴答声\",\n \"cinematography\": \"分镜1:(镜头参数)(例如:特写镜头,85mm焦段)。(光影色调)(例如:**全局暖色调**,晨光金色光泽,高调照明)。(动作)(例如:李明猛地睁开眼睛)。(台词)(若有:角色名: 台词内容)。持续时间:3秒\\n\\n分镜2:(镜头参数)(例如:中景,35mm焦段)。(光影色调)(例如:**延续暖色调**,侧逆光增强轮廓)。(动作)(例如:李明从床上坐起)。(台词)(若有:角色名: 台词内容)。持续时间:7秒\"\n}]\n\\`\\`\\`\n\n--------------------------------\n\n请开始执行",
"hasOutputParser": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2.2,
"position": [
1696,
1968
],
"id": "73232207-723e-44d7-a828-59f5d7c47faf",
"name": "sora2格式的视频分镜脚本",
"retryOnFail": true
},
{
"parameters": {
"jsCode": "const segments = $input.first().json.output;\nconst scenes = segments.map((segment) => {\n const shotsText = segment.shots.join('\\n')\n return `${segment.visual_summary}\\n${shotsText}`\n})\nconst characters = $('分镜数据整理').first().json.characters.map((char) => `${char.name}:${char.description}`).join('\\n')\n\nreturn {\n \"scriptScenesText\": scenes.map((sceneText, index) => `场景${index + 1}:${sceneText}`).join('\\n\\n'),\n \"characters\": characters\n}"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
1440,
1968
],
"id": "f8ef4754-f68f-4f22-97d1-79c50bae52a2",
"name": "Code in JavaScript3"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "5a481b6b-0e74-4cc3-b60d-5a668a68f762",
"name": "video_data",
"value": "={{ $json.data }}",
"type": "array"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
1680,
2464
],
"id": "a1d9c901-4604-4956-bf73-3030ffe5e334",
"name": "生成视频后字段整理"
},
{
"parameters": {
"options": {
"reset": "={{ $json.scene_list.index === 0 }}"
}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
640,
1952
],
"id": "b5f4978c-4bb1-42cf-b5ec-3c23ec8a191e",
"name": "Loop Over Items3"
},
{
"parameters": {
"fieldsToAggregate": {
"fieldToAggregate": [
{}
]
},
"options": {}
},
"type": "n8n-nodes-base.aggregate",
"typeVersion": 1,
"position": [
1936,
2480
],
"id": "276c6fab-f006-42aa-8075-afc4d8d52b7d",
"name": "Aggregate5"
},
{
"parameters": {
"workflowId": {
"__rl": true,
"value": "={{ $('基础字段').first().json['生成分镜图片-批量-工作流id'] }}",
"mode": "id",
"cachedResultUrl": "/workflow/=%7B%7B%20$('%E5%9F%BA%E7%A1%80%E5%AD%97%E6%AE%B5').first().json['%E7%94%9F%E6%88%90%E5%88%86%E9%95%9C%E5%9B%BE%E7%89%87-%E6%89%B9%E9%87%8F-%E5%B7%A5%E4%BD%9C%E6%B5%81id']%20%7D%7D"
},
"workflowInputs": {
"mappingMode": "defineBelow",
"value": {
"image_storyboards": "={{ $json.image_storyboards }}",
"child_workflow_id": "={{ $('基础字段').first().json['生成分镜图片-工作流id'] }}"
},
"matchingColumns": [],
"schema": [
{
"id": "image_storyboards",
"displayName": "image_storyboards",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true
},
{
"id": "child_workflow_id",
"displayName": "child_workflow_id",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "string"
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": true
},
"options": {}
},
"type": "n8n-nodes-base.executeWorkflow",
"typeVersion": 1.2,
"position": [
1040,
2464
],
"name": "Call AI漫剧-生成分镜图片-批量",
"id": "3a701ffa-0c3b-4029-9385-97dbb2a183ad"
},
{
"parameters": {
"workflowId": {
"__rl": true,
"value": "={{ $('基础字段').first().json['生成视频片段-批量-工作流id'] }}",
"mode": "id",
"cachedResultUrl": "/workflow/=%7B%7B%20$('%E5%9F%BA%E7%A1%80%E5%AD%97%E6%AE%B5').first().json['%E7%94%9F%E6%88%90%E8%A7%86%E9%A2%91%E7%89%87%E6%AE%B5-%E6%89%B9%E9%87%8F-%E5%B7%A5%E4%BD%9C%E6%B5%81id']%20%7D%7D"
},
"workflowInputs": {
"mappingMode": "defineBelow",
"value": {
"video_storyboards": "={{ $json.video_storyboards }}",
"child_workflow_id": "={{ $('基础字段').first().json['生成视频片段-工作流id'] }}"
},
"matchingColumns": [],
"schema": [
{
"id": "video_storyboards",
"displayName": "video_storyboards",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true
},
{
"id": "child_workflow_id",
"displayName": "child_workflow_id",
"required": false,
"defaultMatch": false,
"display": true,
"canBeUsedToMatch": true,
"type": "string"
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": true
},
"options": {}
},
"type": "n8n-nodes-base.executeWorkflow",
"typeVersion": 1.2,
"position": [
1440,
2464
],
"name": "Call AI漫剧-生成视频片段-批量",
"id": "9bb69ac2-8d35-4f64-b16f-e2ffc6fd4790"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "a888f60f-3f57-4bce-8ca1-805d85f2b60a",
"name": "story",
"value": "银白的月光洒在海面上,波涛轻轻拍打着礁石。苏瑶站在悬崖边,望着远处那座漂浮在云海之上的空岛。她背后的飞行背包已经充满能量,这次云端探险即将开始。 她是一名气象研究员,这次来到这片神秘的云海区域,是为了寻找传说中的\"天气核心\"。据说这个古老的装置能够预测未来的气候变化。 远处传来几声海鸟的鸣叫,苏瑶启动了背包。随着引擎的轻鸣,她缓缓升空。穿过层层云雾,她终于看到了那座空岛——悬浮在千米高空的石质平台,表面生长着发光的苔藓和奇异的植物。 \"到了。\"她深吸一口气,降落在岛屿边缘。 岛屿中心有一座水晶建筑,苏瑶打开了便携式探照灯。光束扫过四周,墙壁上刻满了古老的气象符号,记录着这个文明对天空的理解。 就在这时,她听到了破空的声音。 \"停下。\"一个冷静的声音传来。 苏瑶转过身,看到一个戴着护目镜的男人悬停在半空中,手中拿着一个能量检测仪。",
"type": "string"
},
{
"id": "f315ef43-6b87-4704-bb8d-c4b1143c5d1c",
"name": "art_style",
"value": "新海诚细腻风格",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
384,
432
],
"id": "53bfb947-afe5-4da7-90da-4184e18b7618",
"name": "视频配置"
},
{
"parameters": {
"content": "分析内容,提取场景",
"height": 960,
"width": 800
},
"type": "n8n-nodes-base.stickyNote",
"position": [
576,
336
],
"typeVersion": 1,
"id": "e3299466-7b85-4fa4-9aec-5fdd74e350ec",
"name": "Sticky Note"
},
{
"parameters": {
"content": "step2 角色、场景图片生成",
"height": 960,
"width": 2000,
"color": 6
},
"type": "n8n-nodes-base.stickyNote",
"position": [
1392,
336
],
"typeVersion": 1,
"id": "9109beb7-d785-4647-9553-a1fa47fb0a32",
"name": "Sticky Note1"
},
{
"parameters": {
"content": "step3 生成图片和视频的分镜提示词",
"height": 1056,
"width": 2816,
"color": 4
},
"type": "n8n-nodes-base.stickyNote",
"position": [
576,
1312
],
"typeVersion": 1,
"id": "6105fc00-226e-4534-9e20-5d81d58a6e1e",
"name": "Sticky Note2"
},
{
"parameters": {
"content": "step4 使用banana pro生成图片,使用sora2生成视频",
"height": 320,
"width": 1648,
"color": 3
},
"type": "n8n-nodes-base.stickyNote",
"position": [
576,
2384
],
"typeVersion": 1,
"id": "4acd46e3-4487-4502-9f28-db3be353fbf8",
"name": "Sticky Note3"
},
{
"parameters": {
"content": "\n欢迎加入我的知识星球,我会持续分享AI相关资讯、使用技巧、工作流等\n\n加入星球后权益:\n1.免费帮助部署工作流\n2.免费咨询AI相关问题\n3.学习更多实用AI使用技巧\n\n加入方式:打开图片扫码领取限量优惠券加入 ↓↓↓\nhttps://zsxq.tos-cn-beijing.volces.com/zsxq_youhuiquan.png",
"height": 368,
"width": 464
},
"type": "n8n-nodes-base.stickyNote",
"position": [
0,
0
],
"typeVersion": 1,
"id": "7483cb0c-11b1-45a8-8eca-a50799290e92",
"name": "Sticky Note4"
}
],
"pinData": {},
"connections": {
"When clicking ‘Execute workflow’": {
"main": [
[
{
"node": "基础字段",
"type": "main",
"index": 0
}
]
]
},
"Structured Output Parser1": {
"ai_outputParser": [
[
{
"node": "AI Agent1",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"AI Agent1": {
"main": [
[
{
"node": "Code in JavaScript",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript": {
"main": [
[
{
"node": "Edit Fields1",
"type": "main",
"index": 0
}
]
]
},
"Edit Fields1": {
"main": [
[
{
"node": "人物",
"type": "main",
"index": 0
},
{
"node": "场景",
"type": "main",
"index": 0
}
]
]
},
"DeepSeek Chat Model2": {
"ai_languageModel": [
[
{
"node": "人物",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Structured Output Parser2": {
"ai_outputParser": [
[
{
"node": "人物",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"Structured Output Parser3": {
"ai_outputParser": [
[
{
"node": "场景",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"人物": {
"main": [
[
{
"node": "Split Out",
"type": "main",
"index": 0
}
]
]
},
"场景": {
"main": [
[
{
"node": "Split Out1",
"type": "main",
"index": 0
}
]
]
},
"基础字段": {
"main": [
[
{
"node": "视频配置",
"type": "main",
"index": 0
}
]
]
},
"Split Out": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[
{
"node": "Aggregate",
"type": "main",
"index": 0
}
],
[
{
"node": "Call 'AI漫剧-文生图'",
"type": "main",
"index": 0
}
]
]
},
"Split Out1": {
"main": [
[
{
"node": "Loop Over Items1",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items1": {
"main": [
[
{
"node": "Aggregate1",
"type": "main",
"index": 0
}
],
[
{
"node": "Call 'AI漫剧-文生图'1",
"type": "main",
"index": 0
}
]
]
},
"Call 'AI漫剧-文生图'1": {
"main": [
[
{
"node": "Edit Fields7",
"type": "main",
"index": 0
}
]
]
},
"Aggregate": {
"main": [
[
{
"node": "Code in JavaScript1",
"type": "main",
"index": 0
}
]
]
},
"Aggregate1": {
"main": [
[
{
"node": "Code in JavaScript2",
"type": "main",
"index": 0
}
]
]
},
"Edit Fields7": {
"main": [
[
{
"node": "Loop Over Items1",
"type": "main",
"index": 0
}
]
]
},
"Edit Fields8": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Merge": {
"main": [
[
{
"node": "Aggregate3",
"type": "main",
"index": 0
}
]
]
},
"DeepSeek Chat Model5": {
"ai_languageModel": [
[
{
"node": "生成剧本分镜描述的提示词",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Aggregate3": {
"main": [
[
{
"node": "角色-场景整理",
"type": "main",
"index": 0
}
]
]
},
"角色-整理": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 0
}
]
]
},
"场景-整理": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 1
}
]
]
},
"Code in JavaScript1": {
"main": [
[
{
"node": "角色-整理",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript2": {
"main": [
[
{
"node": "场景-整理",
"type": "main",
"index": 0
}
]
]
},
"DeepSeek Chat Model6": {
"ai_languageModel": [
[
{
"node": "sora2格式的视频分镜脚本",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"DeepSeek Chat Model3": {
"ai_languageModel": [
[
{
"node": "场景",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Structured Output Parser7": {
"ai_outputParser": [
[
{
"node": "生成剧本分镜描述的提示词",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"Structured Output Parser8": {
"ai_outputParser": [
[
{
"node": "sora2格式的视频分镜脚本",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"DeepSeek Chat Model9": {
"ai_languageModel": [
[
{
"node": "生成图片分镜",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Structured Output Parser9": {
"ai_outputParser": [
[
{
"node": "生成图片分镜",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"生成图片分镜": {
"main": [
[
{
"node": "Code in JavaScript7",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript8": {
"main": [
[
{
"node": "生成图片分镜",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript7": {
"main": [
[
{
"node": "最终图片分镜脚本整理",
"type": "main",
"index": 0
}
]
]
},
"最终图片分镜脚本整理": {
"main": [
[
{
"node": "Call AI漫剧-生成分镜图片-批量",
"type": "main",
"index": 0
}
]
]
},
"DeepSeek Chat Model1": {
"ai_languageModel": [
[
{
"node": "AI Agent1",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"数据整理": {
"main": [
[
{
"node": "Call AI漫剧-生成视频片段-批量",
"type": "main",
"index": 0
}
]
]
},
"Call 'AI漫剧-文生图'": {
"main": [
[
{
"node": "Edit Fields8",
"type": "main",
"index": 0
}
]
]
},
"Split Out2": {
"main": [
[
{
"node": "Loop Over Items2",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items2": {
"main": [
[
{
"node": "Aggregate2",
"type": "main",
"index": 0
}
],
[
{
"node": "获取场景序号和场景对应故事",
"type": "main",
"index": 0
}
]
]
},
"角色-场景整理": {
"main": [
[
{
"node": "Split Out2",
"type": "main",
"index": 0
}
]
]
},
"获取场景序号和场景对应故事": {
"main": [
[
{
"node": "生成场景故事摘要",
"type": "main",
"index": 0
}
]
]
},
"DeepSeek Chat Model": {
"ai_languageModel": [
[
{
"node": "生成场景故事摘要",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Structured Output Parser": {
"ai_outputParser": [
[
{
"node": "生成场景故事摘要",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"Edit Fields2": {
"main": [
[
{
"node": "Loop Over Items2",
"type": "main",
"index": 0
}
]
]
},
"Aggregate2": {
"main": [
[
{
"node": "生成整段故事摘要",
"type": "main",
"index": 0
}
]
]
},
"生成场景故事摘要": {
"main": [
[
{
"node": "Edit Fields2",
"type": "main",
"index": 0
}
]
]
},
"Structured Output Parser4": {
"ai_outputParser": [
[
{
"node": "生成整段故事摘要",
"type": "ai_outputParser",
"index": 0
}
]
]
},
"DeepSeek Chat Model4": {
"ai_languageModel": [
[
{
"node": "生成整段故事摘要",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"生成整段故事摘要": {
"main": [
[
{
"node": "故事摘要整理",
"type": "main",
"index": 0
}
]
]
},
"分镜数据整理": {
"main": [
[
{
"node": "生成剧本分镜描述的提示词",
"type": "main",
"index": 0
}
]
]
},
"故事摘要整理": {
"main": [
[
{
"node": "Edit Fields3",
"type": "main",
"index": 0
}
]
]
},
"Split Out3": {
"main": [
[
{
"node": "Loop Over Items3",
"type": "main",
"index": 0
}
]
]
},
"Edit Fields3": {
"main": [
[
{
"node": "Split Out3",
"type": "main",
"index": 0
}
]
]
},
"生成剧本分镜描述的提示词": {
"main": [
[
{
"node": "Code in JavaScript3",
"type": "main",
"index": 0
}
]
]
},
"sora2格式的视频分镜脚本": {
"main": [
[
{
"node": "Code in JavaScript8",
"type": "main",
"index": 0
}
]
]
},
"Code in JavaScript3": {
"main": [
[
{
"node": "sora2格式的视频分镜脚本",
"type": "main",
"index": 0
}
]
]
},
"生成视频后字段整理": {
"main": [
[
{
"node": "Loop Over Items3",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items3": {
"main": [
[
{
"node": "Aggregate5",
"type": "main",
"index": 0
}
],
[
{
"node": "分镜数据整理",
"type": "main",
"index": 0
}
]
]
},
"Call AI漫剧-生成分镜图片-批量": {
"main": [
[
{
"node": "数据整理",
"type": "main",
"index": 0
}
]
]
},
"Call AI漫剧-生成视频片段-批量": {
"main": [
[
{
"node": "生成视频后字段整理",
"type": "main",
"index": 0
}
]
]
},
"视频配置": {
"main": [
[
{
"node": "AI Agent1",
"type": "main",
"index": 0
}
]
]
}
},
"active": false,
"settings": {
"executionOrder": "v1"
},
"versionId": "05e13823-5e77-4707-9b74-d7dfd2bf7f4c",
"meta": {
"instanceId": "7cbe32103a6ff2d8c5a91f9da918c4e038e89cf9d0ca43bf8f0b67f262cbf12c"
},
"id": "6YdRlB36jZAj6Ppq",
"tags": [
{
"updatedAt": "2025-12-26T08:37:31.987Z",
"createdAt": "2025-12-26T08:37:31.987Z",
"id": "gZ4Yf1CKJAPGykEi",
"name": "ai漫剧"
}
]
}